|
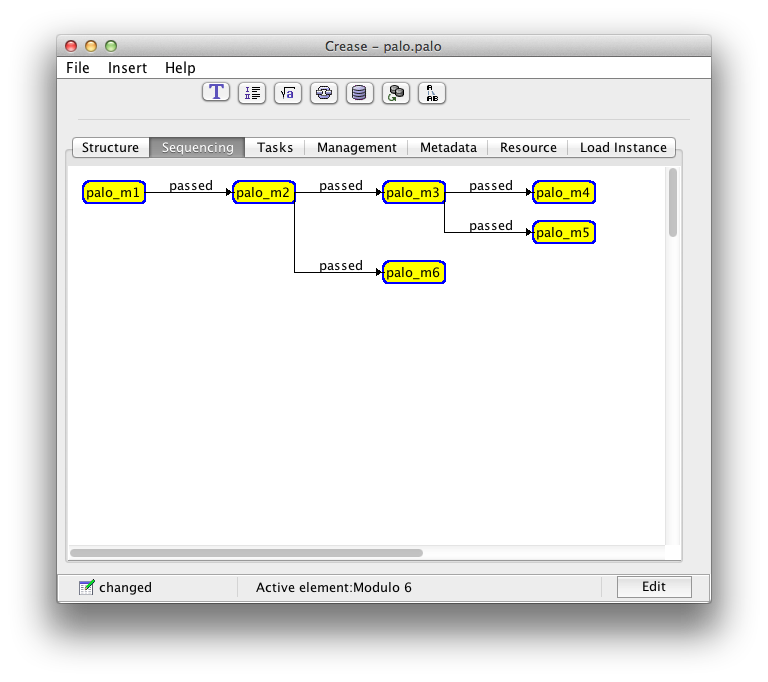
Editor CREASE
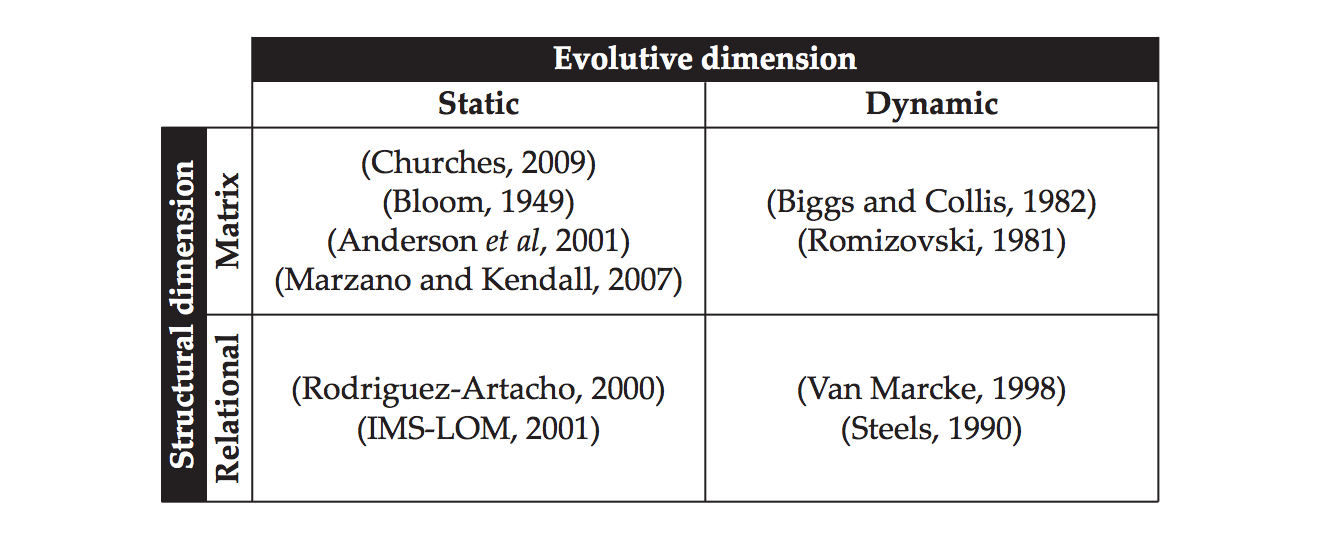
Se han desarrollado ontologías de dominio y clasificaciones para los
recursos educativos basadas en la taxonomía de Bloom. Las ontologías
instruccionales se desarrollan con varios aspectos. Por un lado una
clasificación ortogonal basada en la taxonomía de Bloom que permite la
estructuración de los resultados de búsqueda de la herramienta FCA
(Figura 2). Por otro lado ontologías de dominio de materias
cientifico-técnicas para estructurar los contenidos del repositorio.
En cuanto a prototipos, se ha desarrollado una herramienta basada en
niveles instruccionales (Figura 1) que permite la creación de contenido
instruccional de acuerdo con las capas sobre las que se estructura un
lenguaje de modelado educativo.
Figura 1. Editor CREASE. Vista de la capa se secuenciamiento de un Curso
Figura 2. Taxonomía de Bloom y representación de objetivos didácticos con terminología específica
Módulo de Búsqueda instruccional
Para la
integración en Campus Virtuales, se ha desarrollado un módulo de
búsqueda de recursos educativos basado en FCA. El principal objetivo de
este módulo ha sido el descubrimiento de información útil en Internet
con fines educativos y su posterior organización de manera coherente
con el fin de que los recursos recuperados puedan ser correctamente
explorados. Las tareas y los objetivos de investigación desarrollados
han sido la generación de consultas basadas en objetivos de aprendizaje
y búsqueda de recursos didácticos. En otras palabras, el objetivo de
búsqueda pretende obtener pocos recursos educativos pero muy alineados
con los objetivos didácticos (i.e. una alta precisión) en lugar de una
gran cantidad de recursos relacionados con la temática buscada pero
menos útiles para el diseño de una tarea de aprendizaje (i.e. una alta
cobertura). Además, y dada la naturaleza de la técnica de agrupación
aplicada, la reducción del número de recursos facilita enormemente su
aplicación.
Con este fin, en el proyecto CREASE se ha investigado en la generación
automática de consultas a partir de objetivos de aprendizaje. Más
específicamente, se ha utilizado la taxonomía de Bloom para definir
estas consultas. No obstante, y dado que los objetivos de aprendizaje
definidos en esta taxonomía no resultan útiles a la hora de realizar
consultas sobre motores de búsqueda comerciales (i.e. su terminología
es muy específica del dominio educativo pero no es la terminología con
la que habitualmente se expresan los creadores de contenidos educativos
en Internet), en el proyecto CREASE se ha llevado una representación de
estos objetivos de aprendizaje a partir de bolsas de palabras que han
sido generadas por expertos y que están mucho más acordes con el modo
en el que los generadores de contenidos educativos se expresan al
referirse a éstos en Internet.
El módulo de generación de consultas toma como entrada la necesidad de
información del usuario y enriquece esta consulta inicial con los
términos asociados a cada objetivo de aprendizaje. Las consultas
enriquecidas son utilizadas para recuperar de Internet información que
contenga no solo recursos relacionados con la consulta inicial del
usuario, sino que también se adapten a los distintos objetivos de
aprendizaje. Para ello, se hace uso del API del motor de búsqueda de
Google, permitiendo al usuario recuperar no solo páginas web, sino
también vídeos, imágenes o noticias relacionadas con el objetivo de
búsqueda. Una vez recuperados el conjunto de recursos relacionados con
los objetivos didácticos es necesario llevar a cabo un análisis y
enriquecimiento de los resultados con el fin de llevar a cabo su
representación en función de sus objetivos de aprendizaje y la
terminología asociada a estos.
Para llevar a cabo esta tarea se ha aplicado una aproximación basada en
la ocurrencia de términos en la colección de recursos recuperados. Más
concretamente, nuestra aproximación busca coincidencias entre la
información textual de cada uno de los recursos didácticos recuperados
y la terminología asociada a cada uno de los objetivos de aprendizaje.
Un recurso específico será representado por un objetivo de aprendizaje
solo si contiene alguno de los términos asociados al objetivo de
aprendizaje. Esta aproximación no solo permite caracterizar los
recursos a alto nivel de acuerdo a los objetivos de aprendizaje
descritos en la taxonomía de Bloom, sino también a partir de
terminología mucho más específica relacionada con éstos. Por último,
como resultado del proceso de enriquecimiento descrito es posible
encontrar recursos válidos para diferentes objetivos didácticos. Por
esta razón resulta de gran utilidad la aplicar técnicas de agrupación o
clustering basada en FCA con el fin de facilitar la exploración y
selección por parte del usuario final.
Desde el punto de vista del proyecto, y más específicamente desde el
punto de vista de los objetivos de aprendizaje y el descubrimiento de
contenidos, el Análisis de Conceptos Formales se convierte en una
aproximación muy válida para organizar y clasificar de manera
automática todos los recursos recuperados y enriquecidos en las fases
anteriores. Una aproximación similar se ha aplicado con éxito
facilitando las tareas de exploración en escenarios de Recuperación de
Información.
El resultado de aplicar Análisis de Conceptos Formales es
un retículo de conceptos donde cada nodo puede ser entendido como un
cluster que agrupa un conjunto de recursos recuperados de Internet y
que está descrito por los objetivos de aprendizaje asociados a dichos
recursos. Como puede observarse en la Figura 3, la estructura de
retículo muestra el conjunto de clusters de acuerdo a un esquema de
generalización-especialización y resulta ser mucho mós rica en
comparación con otras estructuras similares como, por ejemplo, las
jerarquías.
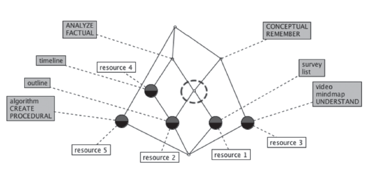
Figura 3. Estructura de un retículo obtenido aplicando FCA
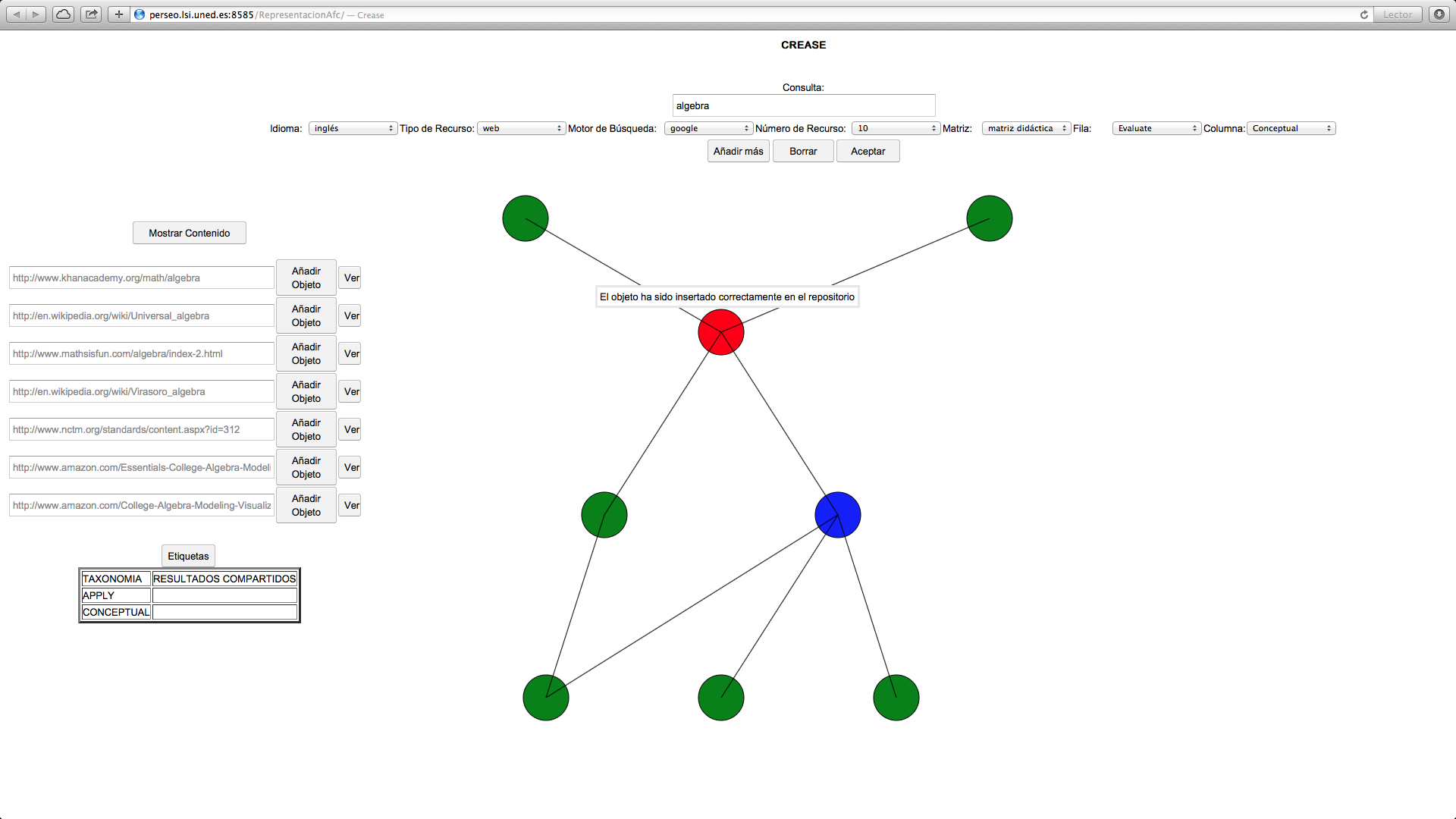
A lo largo del proyecto se han realizado dos prototipos basados en
estas tareas. El primero de ellos ha sido desarrollado utilizando
tecnología GWT y recoge el proceso completo de consulta, análisis y
organización a través de una interfaz web (Figura 4). Con el fin de
desacoplar la lógica de cada uno de los procesos de su representación
final, en el proyecto se ha optado por implementar cada una de las
tareas más complejas como servicios web REST.
Esto facilita enormemente
la reutilización e integración de estos servicios por parte de otras
plataformas educativas. No obstante, y con el fin de demostrar la
viabilidad de integrar la herramienta completa en un campus virtual,
este prototipo ha sido integrado con éxito en el Campus Virtual de la
UCM.
Figura 4. Módulo de descubrimiento de recursos didáticos en Internet
El módulo de búsqueda permite también la insercion de los resultados de búsqueda en el repositorio semántico.
El servicio de búsqueda se lanza desde la aplicación Editor CREASE y también desde la URL
http://perseo.lsi.uned.es:8585/RepresentacionAfc/
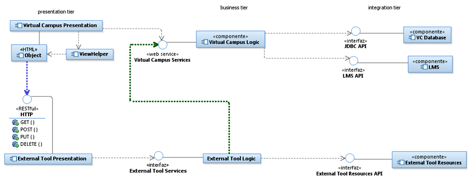
En cuanto al a integración de estas herramientas con la UCM la
Figura 5 describe la arquitectura de esta integración (accesible en http://solaris.fdi.ucm.es/CVMB2/
en con usuario demo y clave demoKey), que aparece descrita en el
segundo artículo publicado en la revista indexada en JCR Journal of
Educational Technology and Society (Ver Publicaciones).
Figura
5 Arquitectura de integracion entre el campus virtual UCM y
herramientas satélite, como la desarrollada en el suproyecto UNED
|